edited README to include run instructions
This commit is contained in:
parent
7d8d4857e0
commit
fd89e902f9
2 changed files with 8 additions and 2 deletions
|
|
@ -1,5 +1,11 @@
|
||||||
# USGS NWIS data visualizations
|
# USGS NWIS data visualizations
|
||||||
|
|
||||||
gets river discharge data from the USGS NWIS and makes visualizations
|
Gets river discharge data from the USGS NWIS and makes visualizations
|
||||||
|
|
||||||
|
**To run: **
|
||||||
|
1. Clone the repository
|
||||||
|
2. Change the working directory in line 6 of `USGS_NWIS.R`. The script will make the `data` and `figures` directory in the working directory. 10 rivers will generate ~100MB of total data and figures.
|
||||||
|
3. Edit the list of rivers and their respective site IDs in `river_IDs.csv`
|
||||||
|
4. Run the script. The intitial download of the data will take some time. Subsequent runs will just download new data.
|
||||||
|
|
||||||
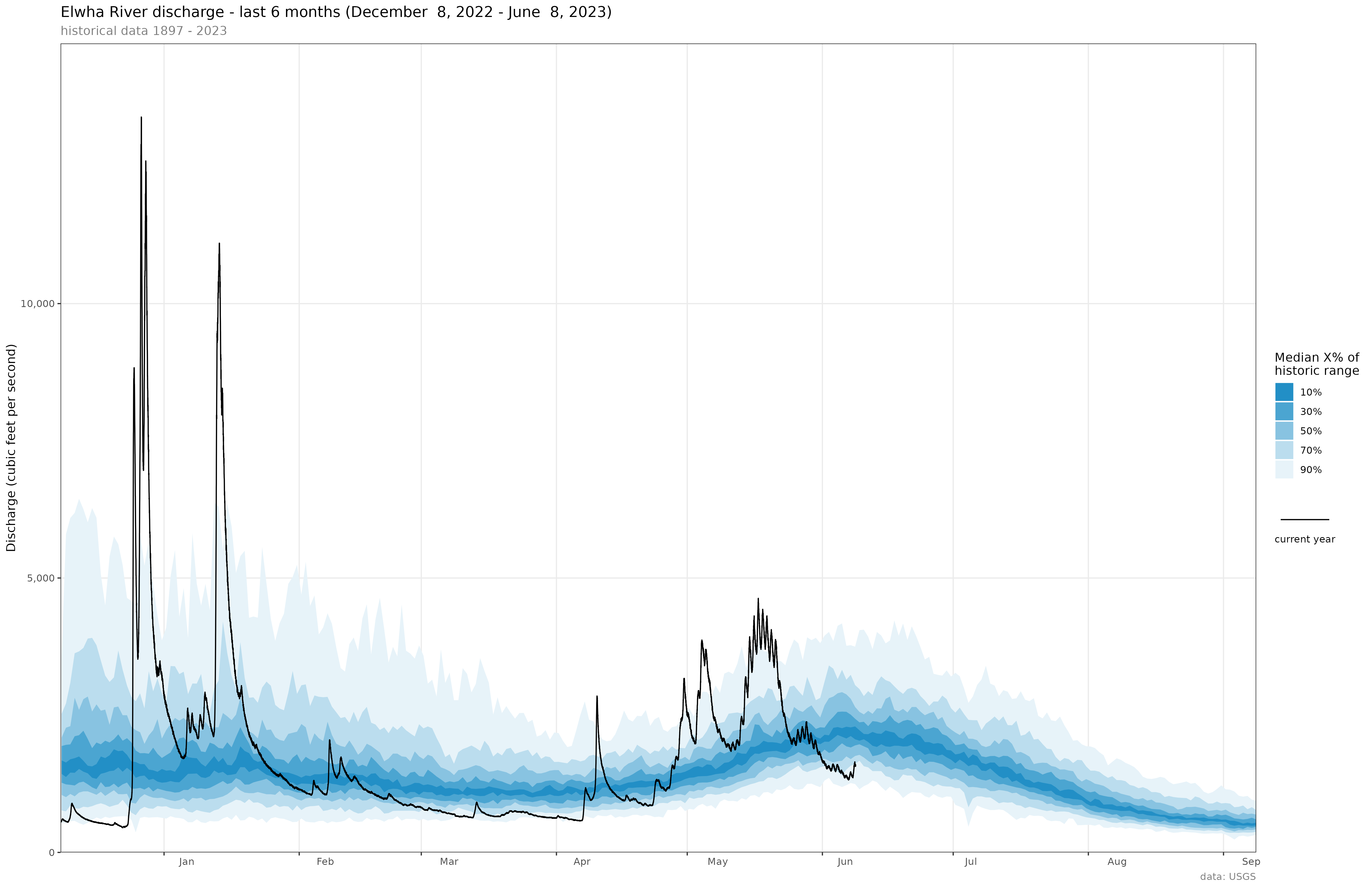
|

|
||||||
|
|
|
||||||
|
|
@ -7,7 +7,7 @@ setwd("/home/ben/Documents/dataProjects/USGS_NWIS")
|
||||||
|
|
||||||
rivers <- read_csv(file = "river_IDs.csv", col_types = c("c", "c"))
|
rivers <- read_csv(file = "river_IDs.csv", col_types = c("c", "c"))
|
||||||
|
|
||||||
rivers <- rivers %>% filter(names %in% c("Elwha"))
|
#rivers <- rivers %>% filter(names %in% c("Elwha"))
|
||||||
#rivers <- rivers %>% filter(names %in% c("Duckabush"))
|
#rivers <- rivers %>% filter(names %in% c("Duckabush"))
|
||||||
#rivers <- rivers %>% filter(names %in% c("Hoh"))
|
#rivers <- rivers %>% filter(names %in% c("Hoh"))
|
||||||
|
|
||||||
|
|
|
||||||
Loading…
Add table
Add a link
Reference in a new issue